Publications
Visual Reasoning over Time Series via Multi-Agent System Pinned Under Review Featured
Weilin Ruan, Yuxuan Liang
Under Review. 2026
We propose MAS4TS, a tool-driven multi-agent framework for general time-series tasks under an Analyzer-Reasoner-Executor paradigm. It integrates visual reasoning over time-series plots, latent trajectory reconstruction, and gated inter-agent communication to improve cross-task generalization and inference efficiency.
Paper Time Series Multi-Agent Systems Visual Reasoning
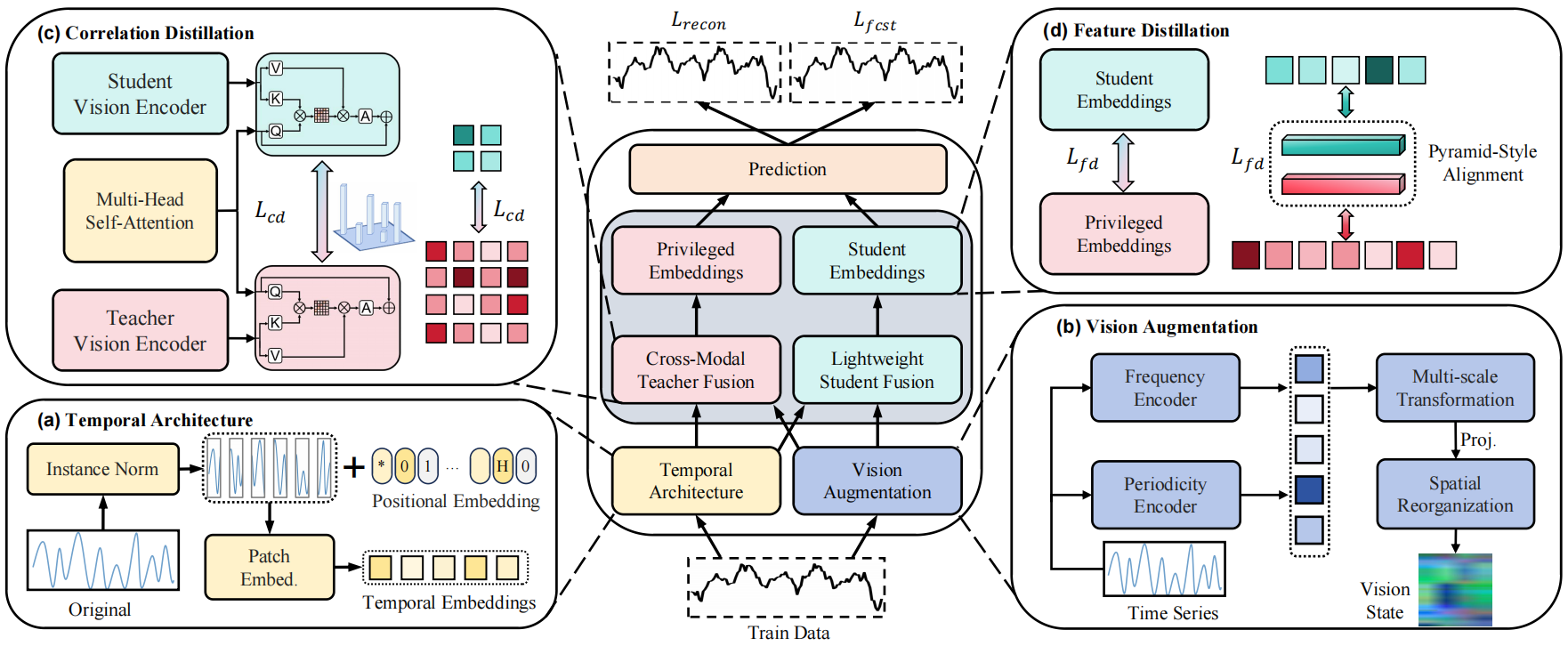
OccamVTS: Distilling Vision Models to 1% Parameters for Time Series Forecasting Pinned Featured
Sisuo Lyu, Siru Zhong, Weilin Ruan, Qingxiang Liu, Qingsong Wen, Hui Xiong, Yuxuan Liang
AAAI. 2026
We propose OccamVTS, a novel framework that distills large vision models to only 1% of their original parameters for efficient time series forecasting, demonstrating that extreme parameter reduction can be achieved while maintaining strong predictive performance through innovative distillation techniques.
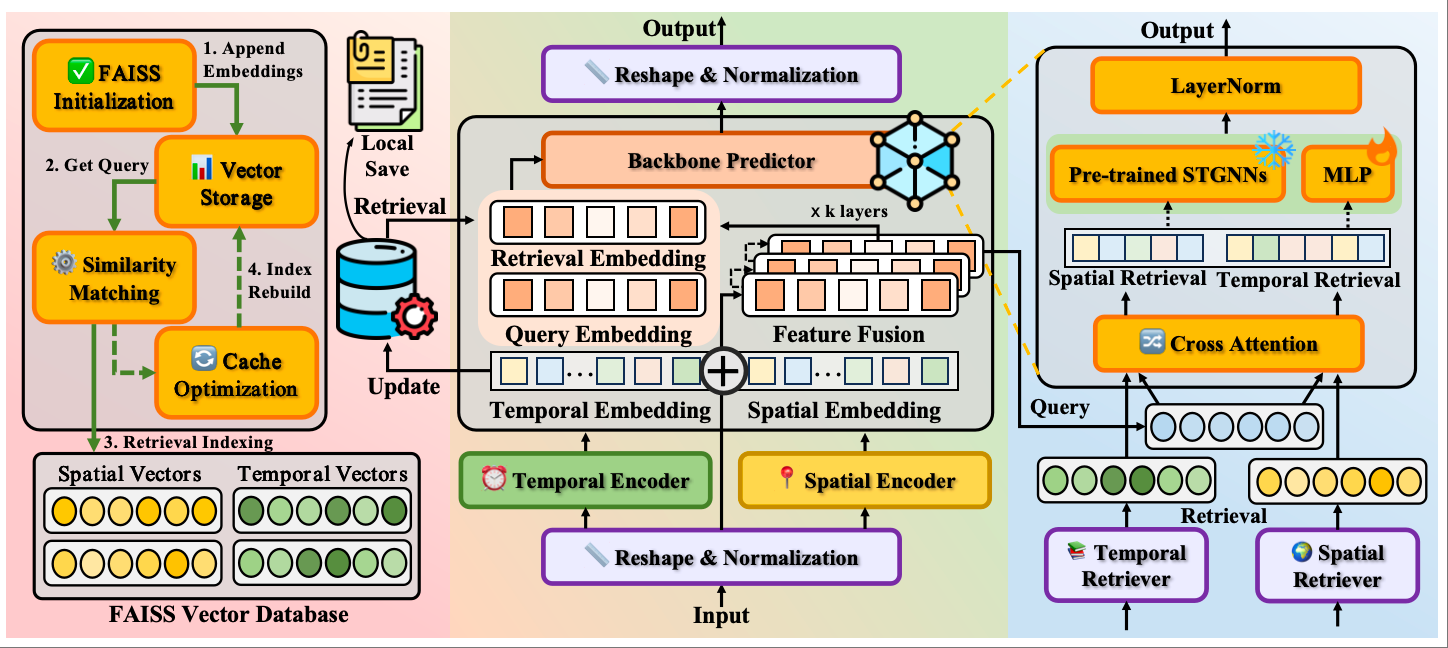
Retrieval Augmented Spatio-Temporal Framework for Traffic Prediction Pinned Featured
Weilin Ruan, Xilin Dang, Ziyu Zhou, Sisuo Lyu, Yuxuan Liang
AAAI. 2026
We propose RAST, a universal framework that integrates retrieval-augmented mechanisms with spatio-temporal modeling to address limited contextual capacity and low predictability in traffic prediction. Our framework consists of three key designs: Decoupled Encoder and Query Generator, Spatio-temporal Retrieval Store and Retrievers, and Universal Backbone Predictor that flexibly accommodates pre-trained STGNNs or simple MLP predictors.
Paper Code Spatio-temporal Traffic Prediction Retrieval-Augmented
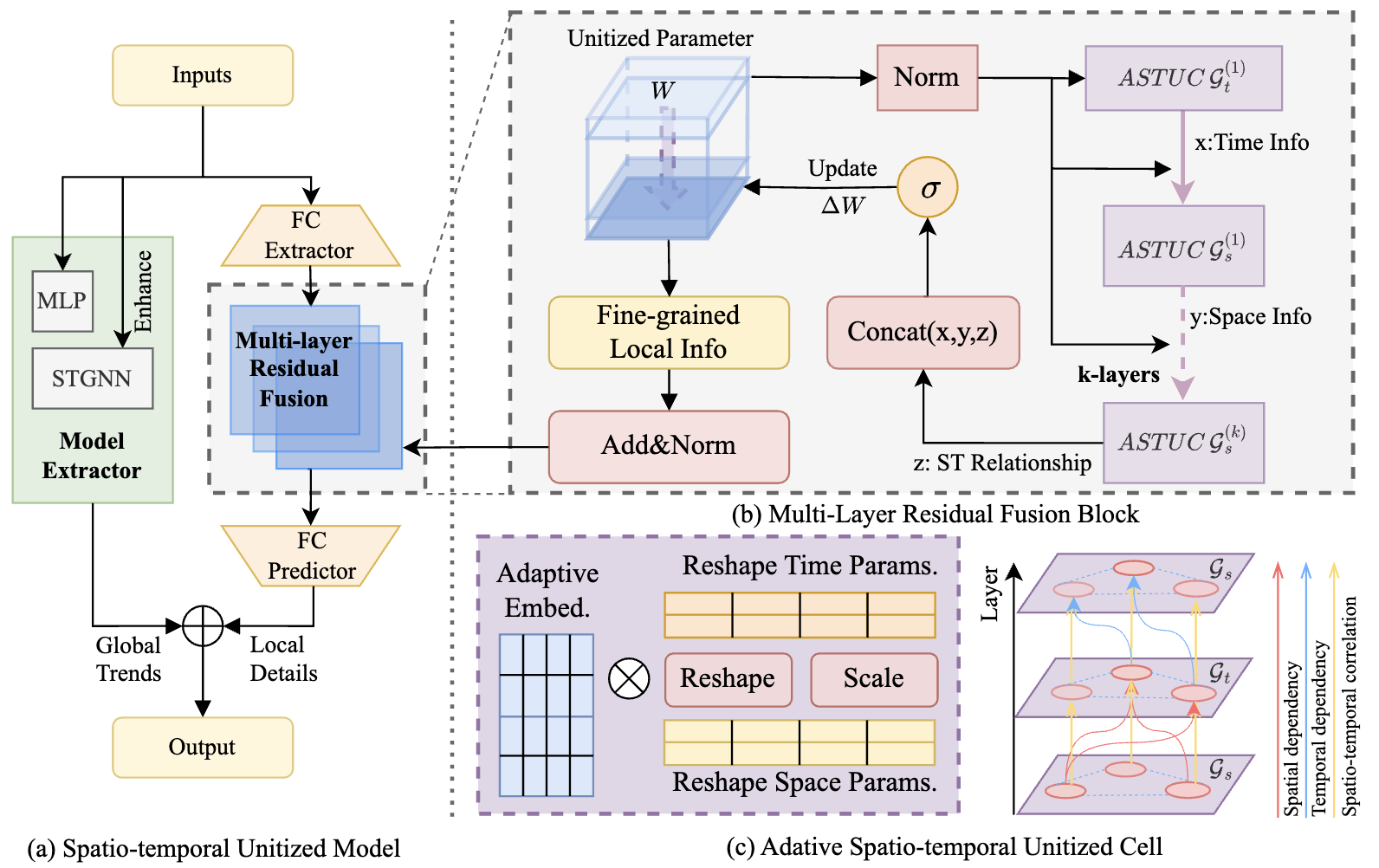
Cross Space and Time: A Spatio-Temporal Unitized Model for Traffic Flow Forecasting Pinned Featured
Weilin Ruan, Wenzhuo Wang, Siru Zhong, Wei Chen, Li Liu, Yuxuan Liang
TITS. 2025
This paper proposes a novel spatio-temporal unitized model for traffic flow forecasting that effectively captures complex dependencies across both space and time dimensions, achieving state-of-the-art performance on multiple benchmark datasets.
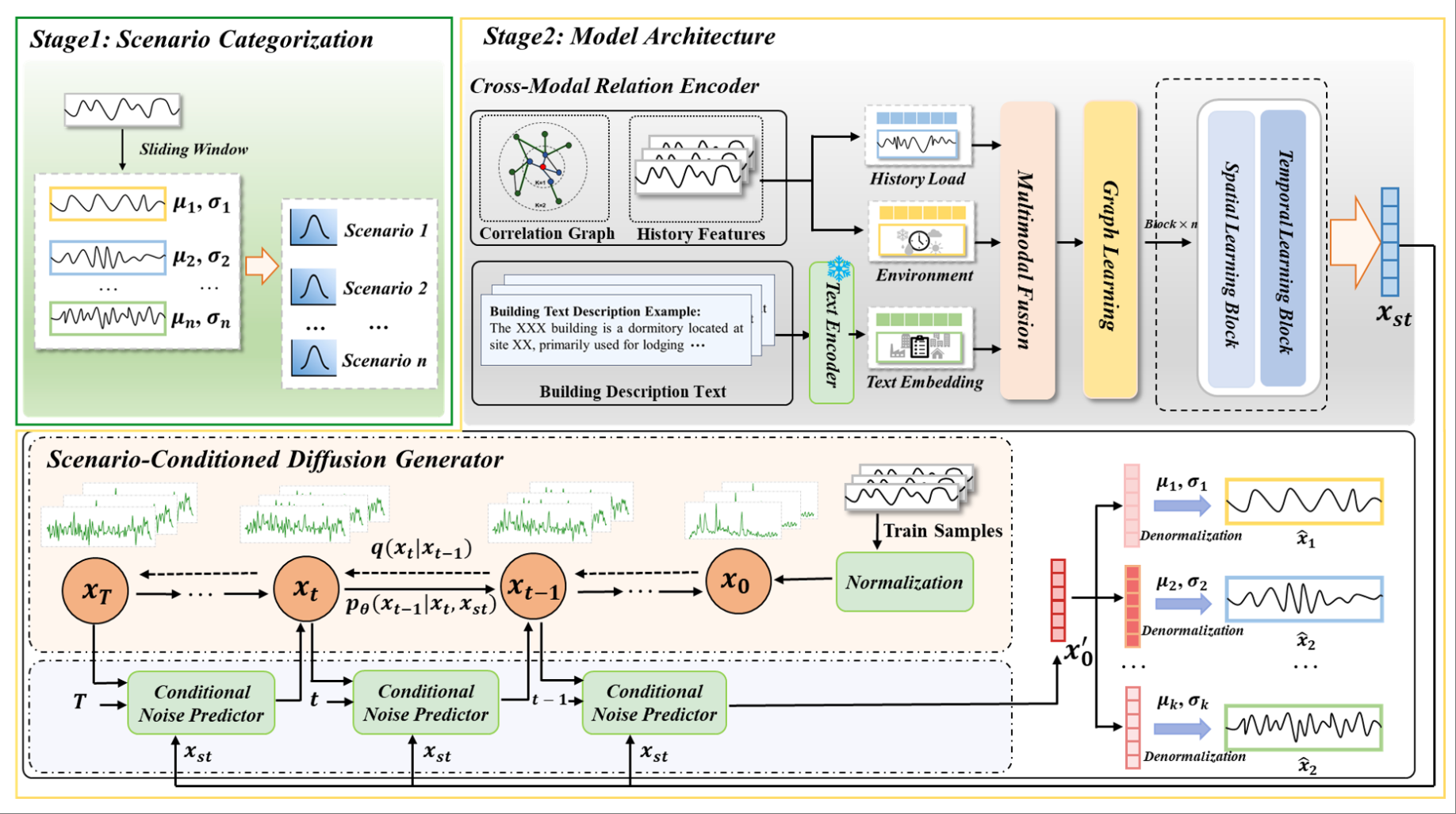
Towards Multi-Scenario Forecasting of Building Electricity Loads with Multimodal Data Pinned Featured
Yongzheng Liu, Siru Zhong, Gefeng Luo, Weilin Ruan, Yuxuan Liang
ACM MM. 2025
We propose MMLoad, a novel diffusion-based multimodal framework for multi-scenario building load forecasting with three innovations: Multimodal Data Enhancement Pipeline, Cross-modal Relation Encoder, and Scenario-Conditioned Diffusion Generator with uncertainty quantification, establishing a new paradigm for multimodal learning in smart energy systems.
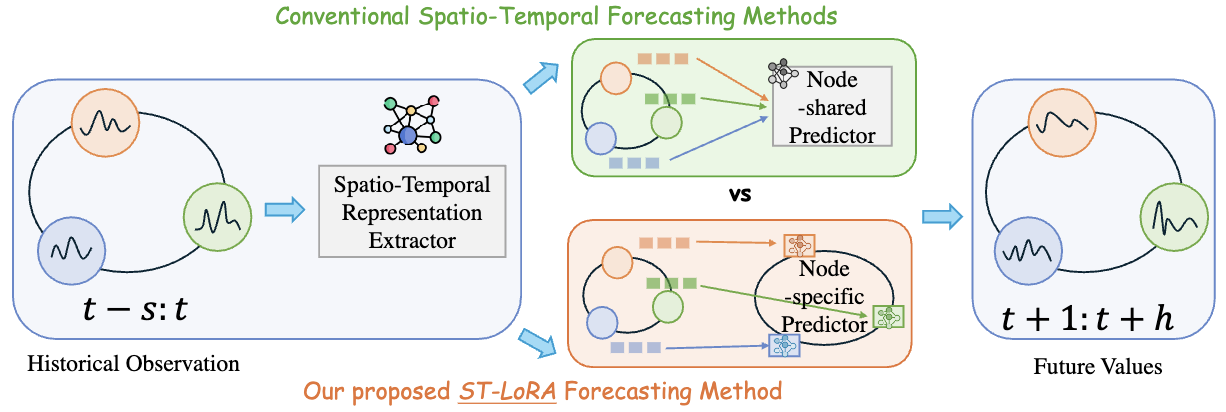
Low-rank Adaptation for Spatio-Temporal Forecasting Pinned Featured Oral
Weilin Ruan, Wei Chen, Xilin Dang, Jianxiang Zhou, Weichuang Li, Xu Liu, Yuxuan Liang
ECML. 2025
This paper presents ST-LoRA, a novel low-rank adaptation framework as an off-the-shelf plugin for existing spatial-temporal prediction models, which alleviates node heterogeneity problems through node-level adjustments while minimally increasing parameters and training time.
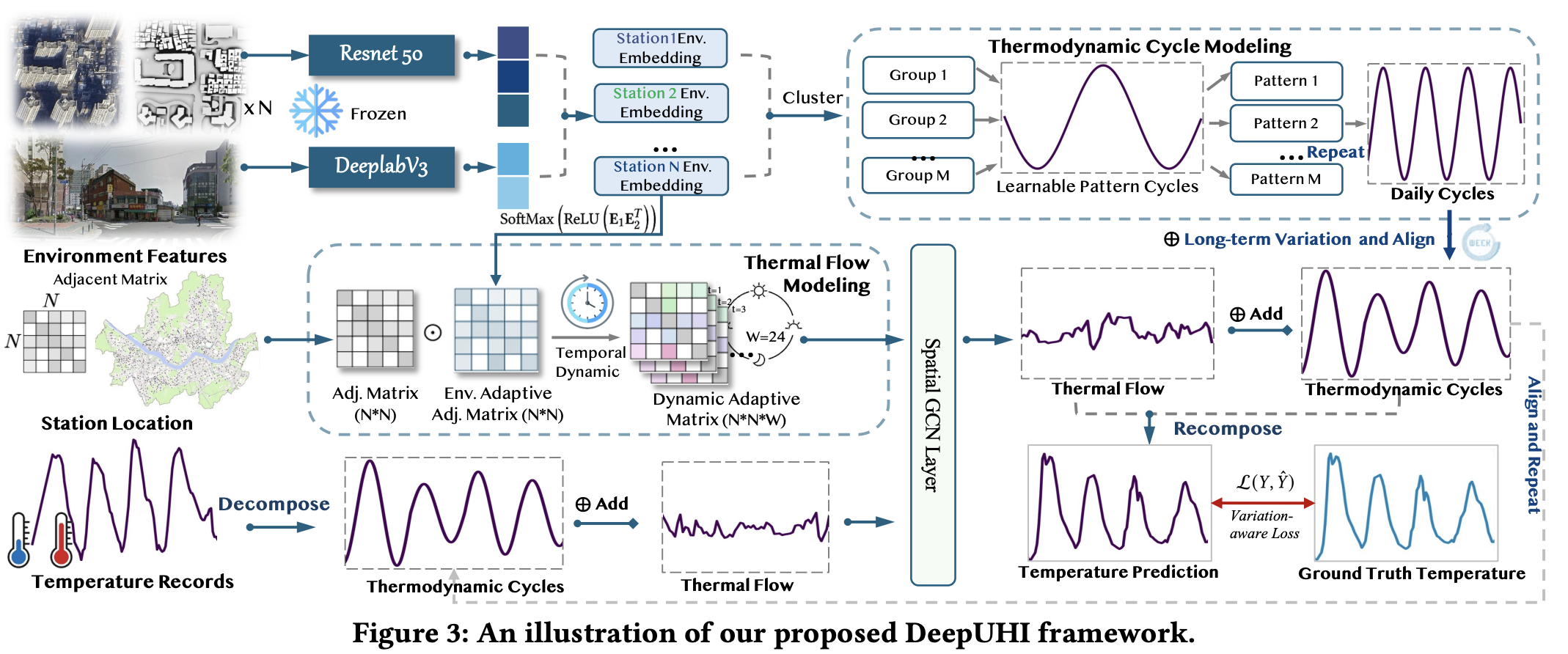
Fine-grained Urban Heat Island Effect Forecasting: A Context-aware Thermodynamic Modeling Framework Pinned Featured
Xingchen Zou, Weilin Ruan, Siru Zhong, Yuehong HU, Yuxuan Liang
KDD. 2025
We present DeepUHI, a heat equation-based framework that models urban heat island effects through thermodynamic cycles and thermal flows, integrating multimodal environmental data to achieve precise street-level temperature forecasting, now deployed as a real-time warning system in Seoul.
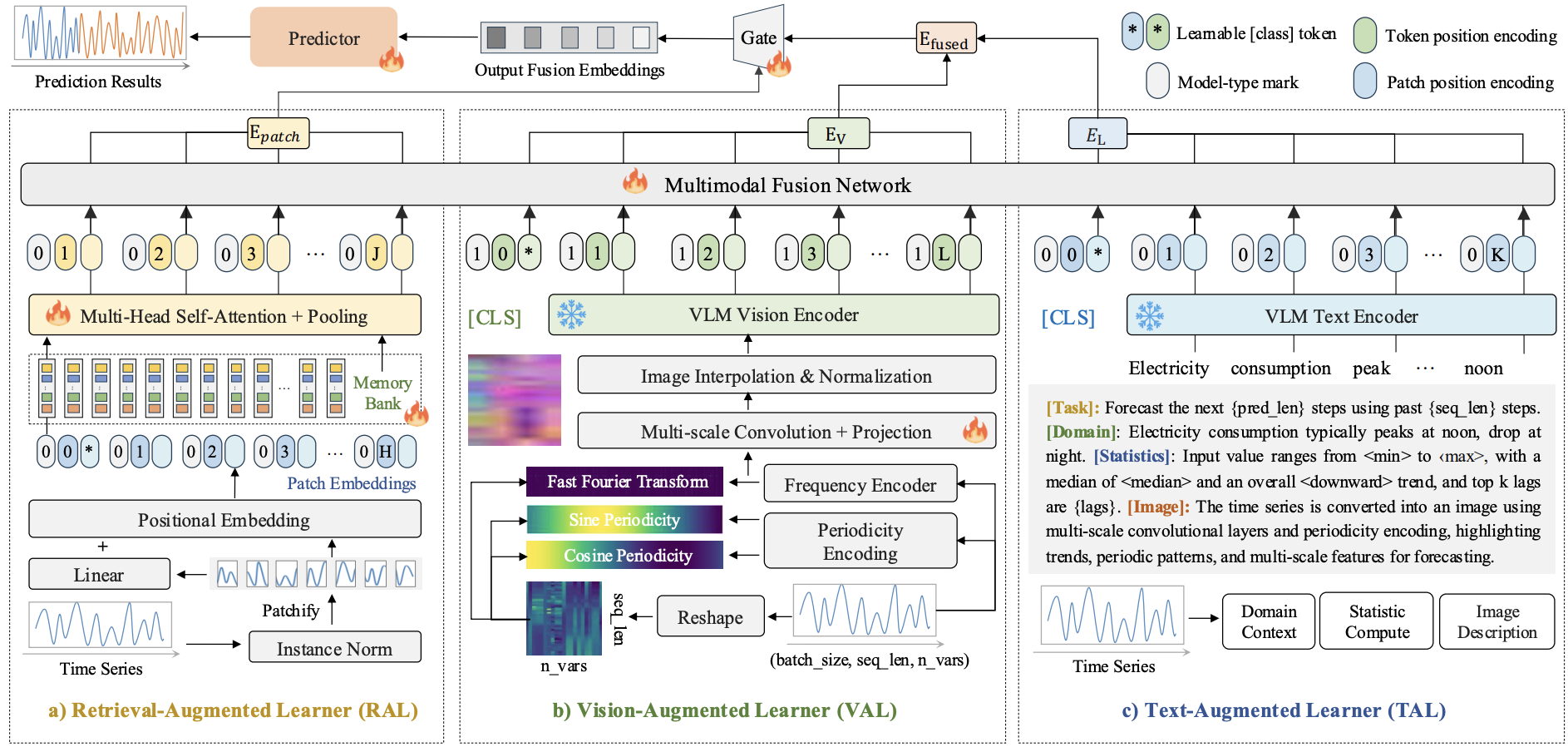
Time-VLM: Exploring Multimodal Vision-Language Models for Augmented Time Series Forecasting Pinned Featured
Siru Zhong, Weilin Ruan, Ming Jin, Huan Li, Qingsong Wen, Yuxuan Liang
ICML. 2025
This paper proposes Time-VLM, a novel multimodal framework that leverages pre-trained Vision-Language Models (VLMs) to bridge temporal, visual, and textual modalities for enhanced time series forecasting.
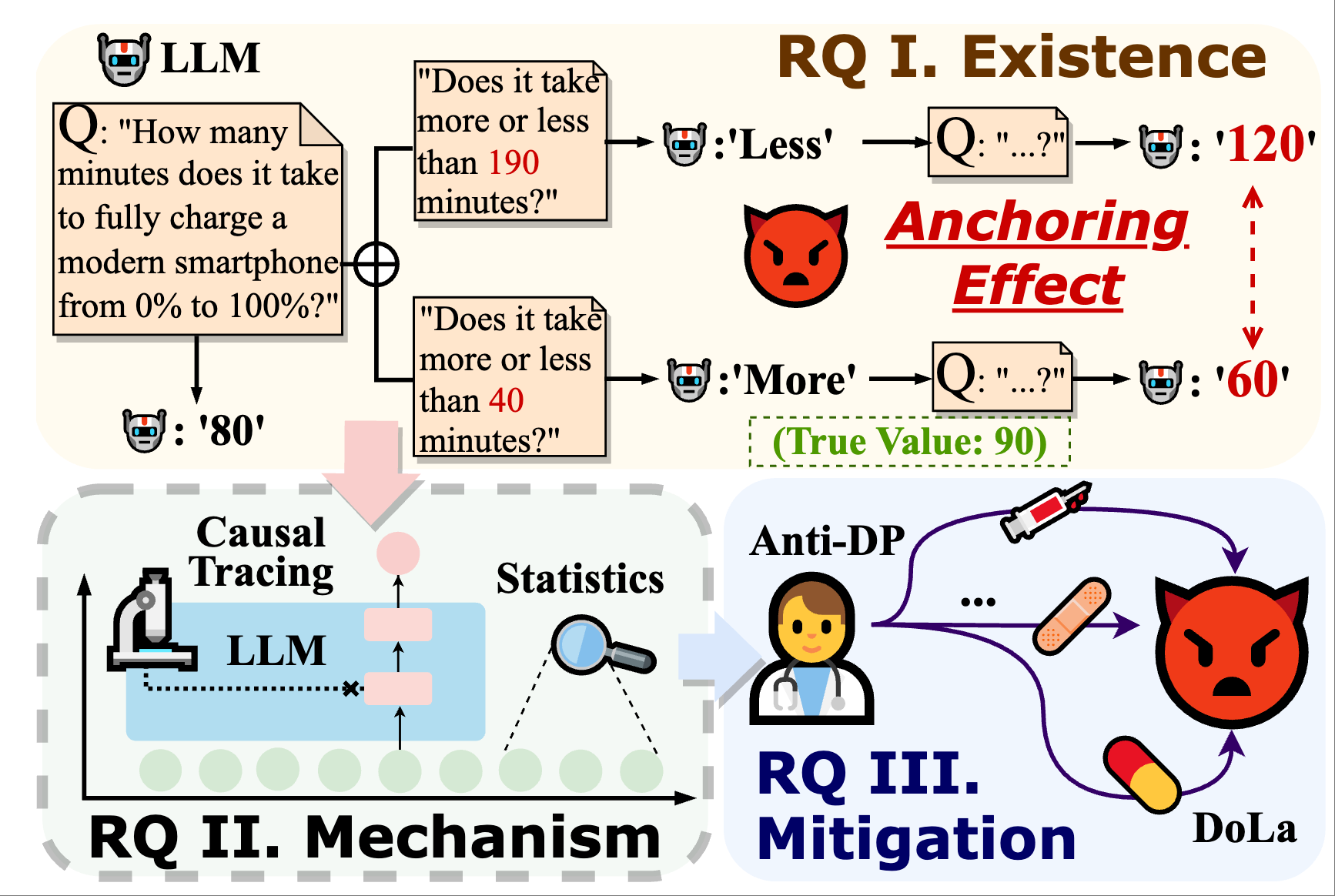
An Empirical Study of the Anchoring Effect in LLMs: Existence, Mechanism, and Potential Mitigations Featured
Yiming Huang, Biquan Bie, Zuqiu Na, Weilin Ruan, Songxin Lei, Yutao Yue, Xinlei He
ICLR Workshop HCAIR. 2026
We investigate the anchoring effect in Large Language Models, exploring whether LLMs are affected by anchoring bias, the underlying mechanisms, and potential mitigation strategies. We introduce SynAnchors dataset and show that LLMs' anchoring bias exists commonly with shallow-layer acting and is not eliminated by conventional strategies, while reasoning can offer some mitigation.
Paper Natural Language Processing Cognitive Bias Large Language Models

VQualA 2025 Challenge on Face Image Quality Assessment: Methods and Results Featured
Sizhuo Ma, ... (60+ authors), Weilin Ruan, Yutao Yue
ICCV Workshop. 2025
We introduce the VQualA 2025 Challenge on Face Image Quality Assessment, part of ICCV 2025 Workshops. Participants developed efficient models (<0.5 GFLOPs, <5M parameters) predicting Mean Opinion Scores (MOS) under realistic degradations. The challenge attracted 127 participants, resulting in 1519 valid final submissions, contributing to practical FIQA solutions.
Paper Computer Vision Image Quality Assessment Face Analysis
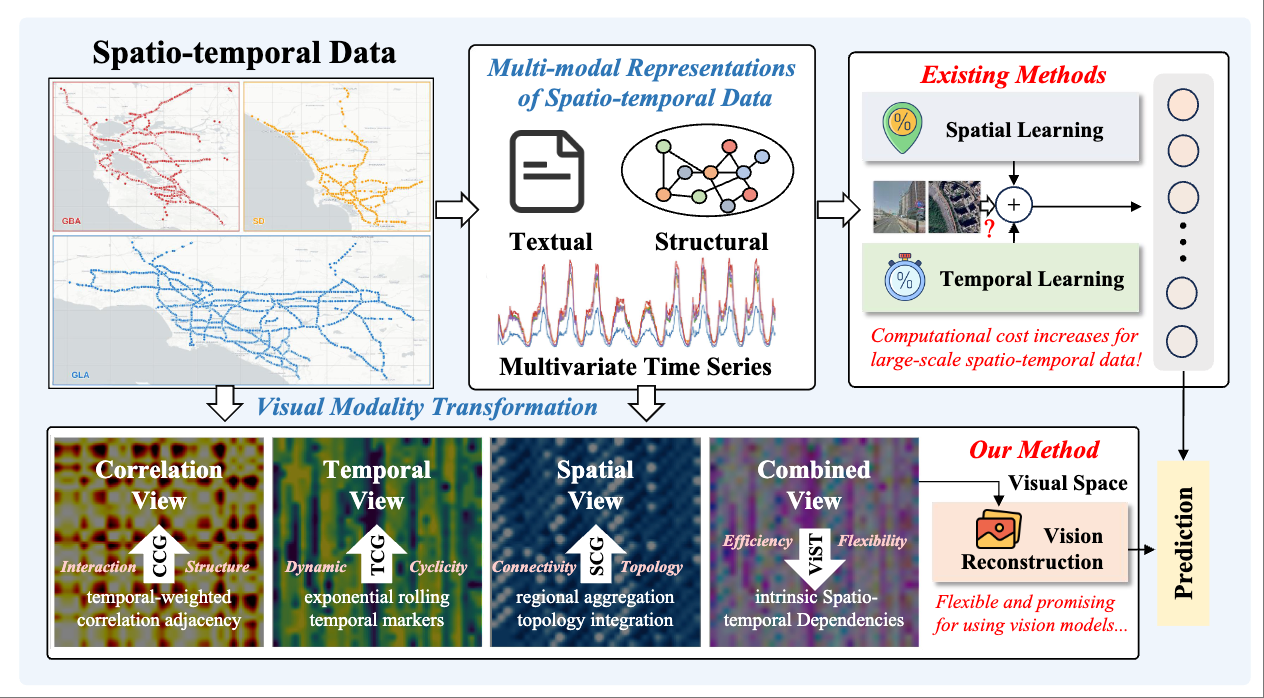
ViST: Harnessing Vision Transformation and Reconstruction for Multi-modal Spatio-temporal Forecasting Featured
Weilin Ruan, Siru Zhong, Haomin Wen, Songxin Lei, Yongzheng Liu, Xingchen Zou, Yuxuan Liang
Under Review. 2025
We propose ViST, a novel vision-driven framework that transforms raw spatio-temporal data directly into a low-dimensional visual space for more effective and scalable forecasting. Our method features Multi-view Vision Transformation, Multi-modal Conditional Reconstruction, and Efficient Cross-modal Fusion Mechanism, achieving state-of-the-art accuracy with significantly reduced computational cost.
Paper Code Spatio-temporal Multi-modal Vision Transformation
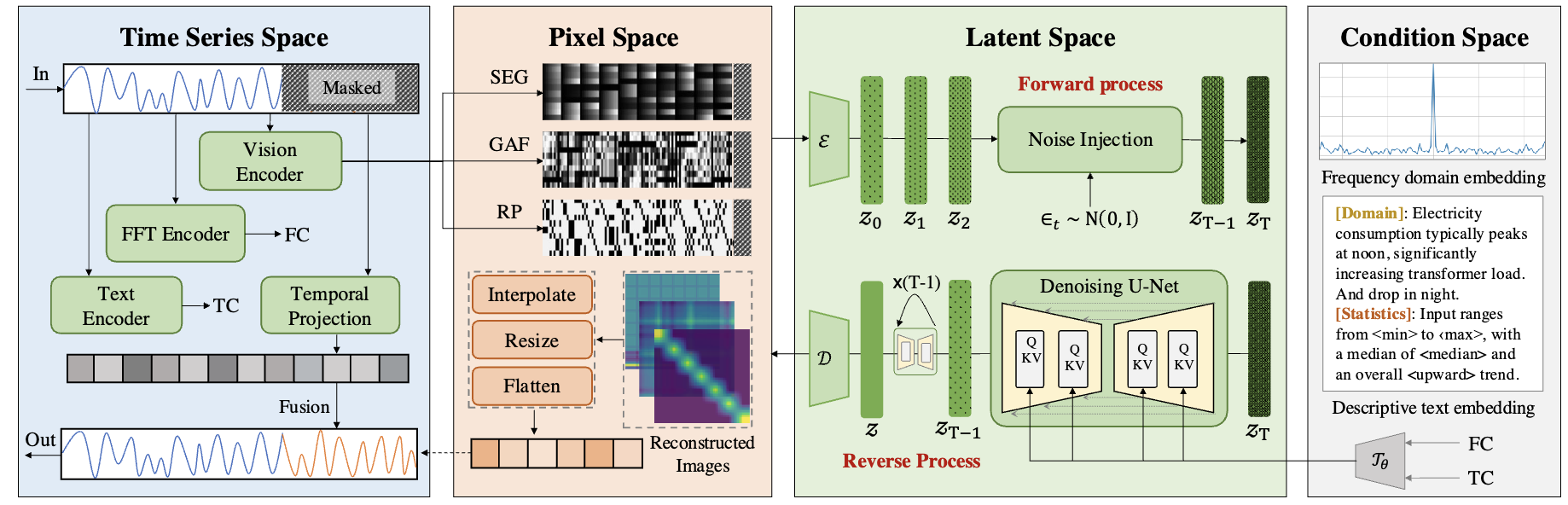
LDM4TS: Latent Diffusion Model for Time Series Forecasting Featured
Weilin Ruan, Siru Zhong, Haomin Wen, Yuxuan Liang
Under review. 2025
This paper introduces LDM4TS, a novel latent diffusion model for time series forecasting that transforms time series into multiple image representations and leverages diffusion models to enhance forecasting capabilities.
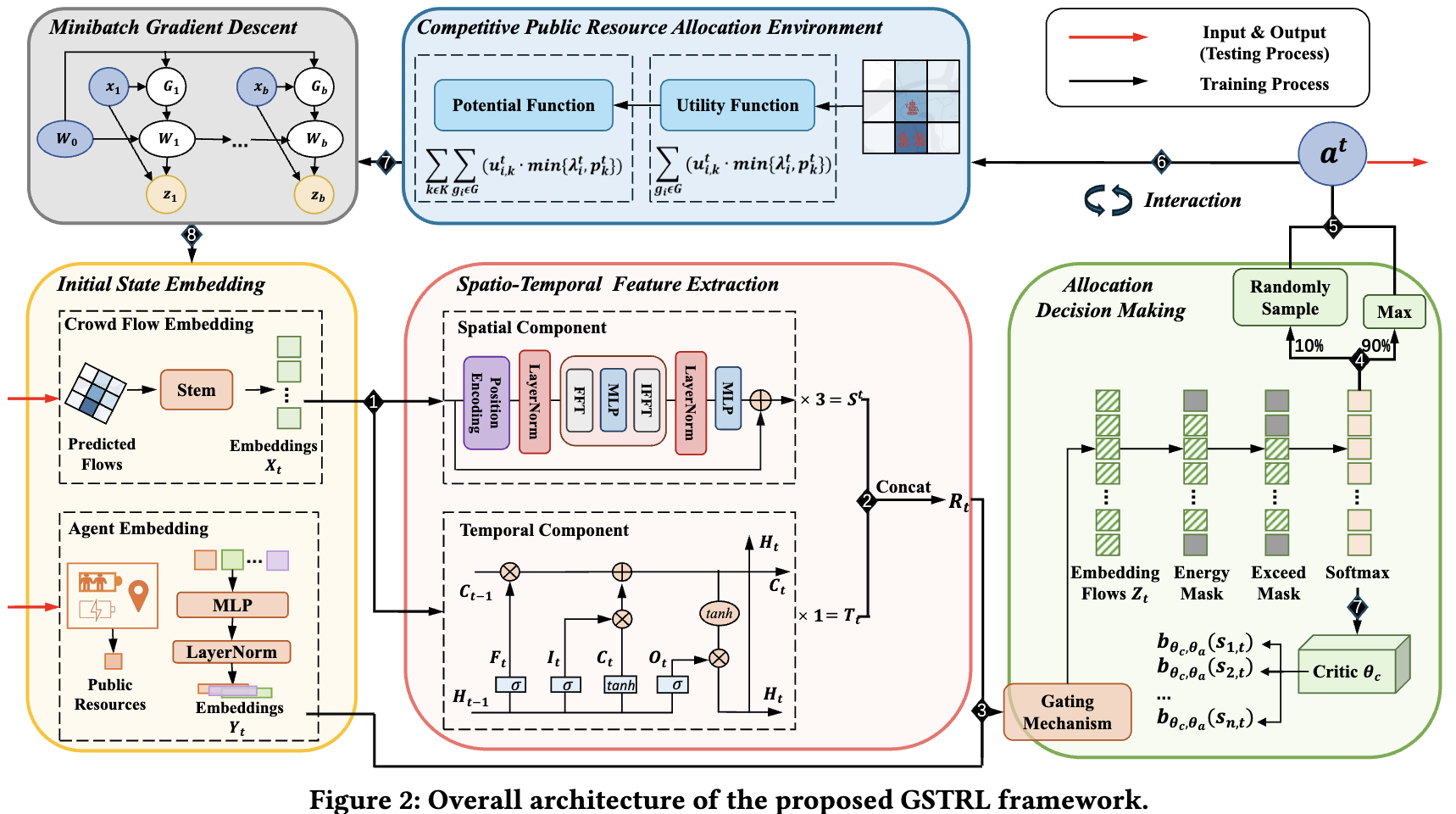
A Game-Theoretic Spatio-Temporal Reinforcement Learning Framework for Collaborative Public Resource Allocation Featured
Songxin Lei, Qiongyan WANG, Yanchen ZHU, Hanyu Yao, Sijie Ruan, Weilin Ruan, Yuyu Luo, Yuxuan Liang
Under review. 2024
We introduce GSTRL, a novel game-theoretic reinforcement learning framework that addresses collaborative public resource allocation by modeling it as a cooperative potential game and incorporating spatio-temporal learning to capture crowd dynamics, outperforming existing methods on real-world datasets.
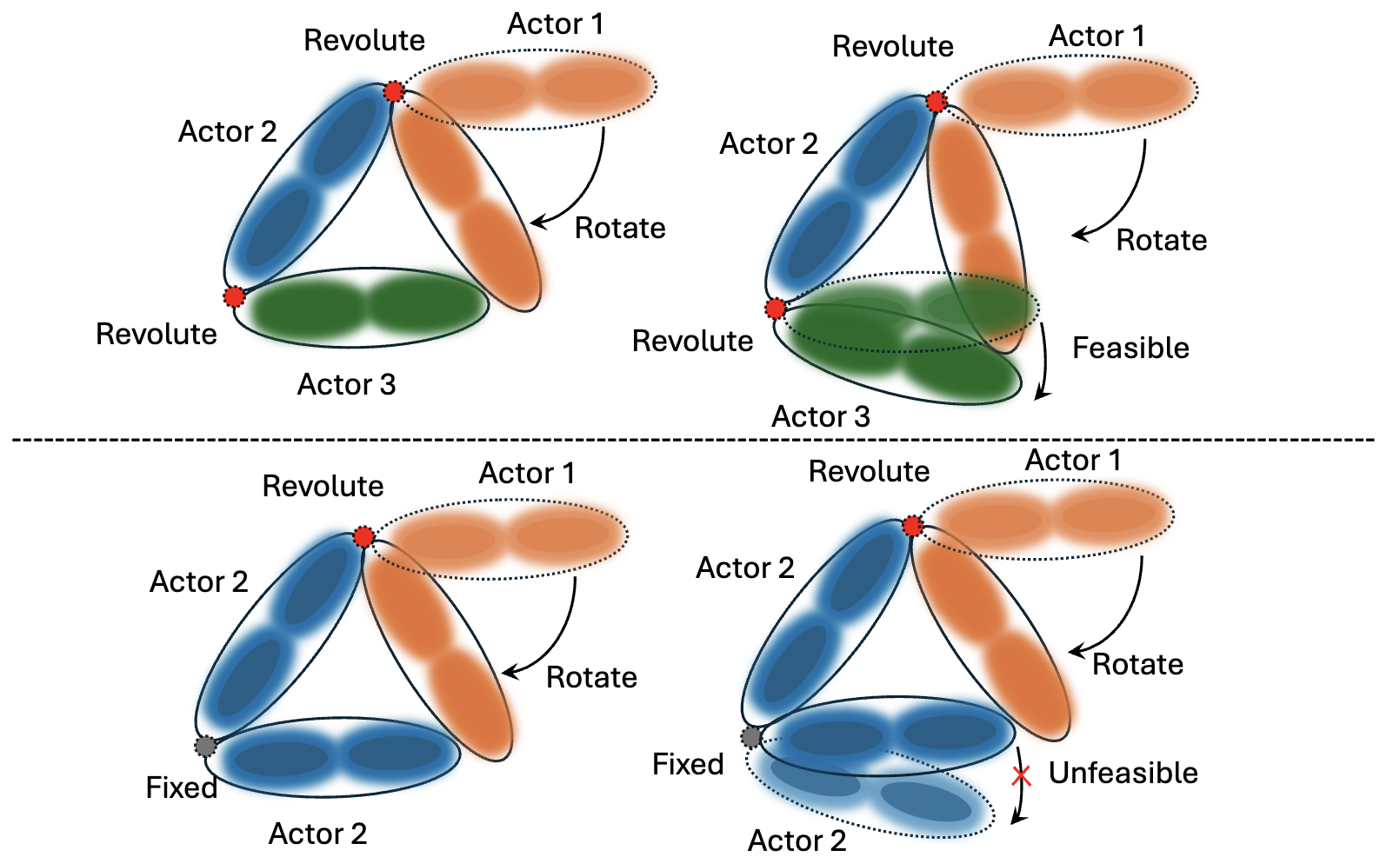
Kinematics-based Object Articulation with Gaussian Splatting Featured
Weichuang Li, Weilin Ruan, Xuechao Zhang, Yuxuan Liang
Under review. 2024
We present a novel approach that combines Gaussian Splatting with kinematic knowledge to reconstruct and simulate articulated objects, enhancing both geometric detail and articulation dynamics while overcoming the limitations of previous implicit-based models.
Paper Computer Vision